AlphaStar算法梳理
AlphaStar整理
- 对AlphaStar算法的解读:
- https://zhuanlan.zhihu.com/p/92543229
- https://zhuanlan.zhihu.com/p/97720096
- https://zhuanlan.zhihu.com/p/89396146
- 原论文:https://sci-hub.se/10.1038/s41586-019-1724-z
- 论文解读视频:https://www.bilibili.com/video/BV1wa4y1e74G/?spm_id_from=333.337.search-card.all.click&vd_source=54a0edf8490a6a72a5e82c4e543fc3e2
1. 监督学习(预训练过程)
通过大量的高质量人类对局作为经验数据,进行学习,实现模仿学习的效果,即在一个状态下,让agent所作的策略去拟合游戏玩家的所作的策略,从而给网络一个较好的初始化参数。
监督学习做法:
对对局进行解码,获得observations。
将observations送入网络,得到action的概率分布
将agent的action概率分布与人类经验的action损失训练:
- 若为分类任务即动作类型选择,则为crossentropy损失
- 若为连续型数值拟合任务,则为mse
在实际训练时,若agent此刻做出的action与人类经验不同,那么在真正执行action时,采取的仍然为人类经验的action,即在整个训练的过程中,不管agent输出什么动作,在执行时均为人类经验动作,agent的动作只做为损失值进行训练。
2. 强化学习
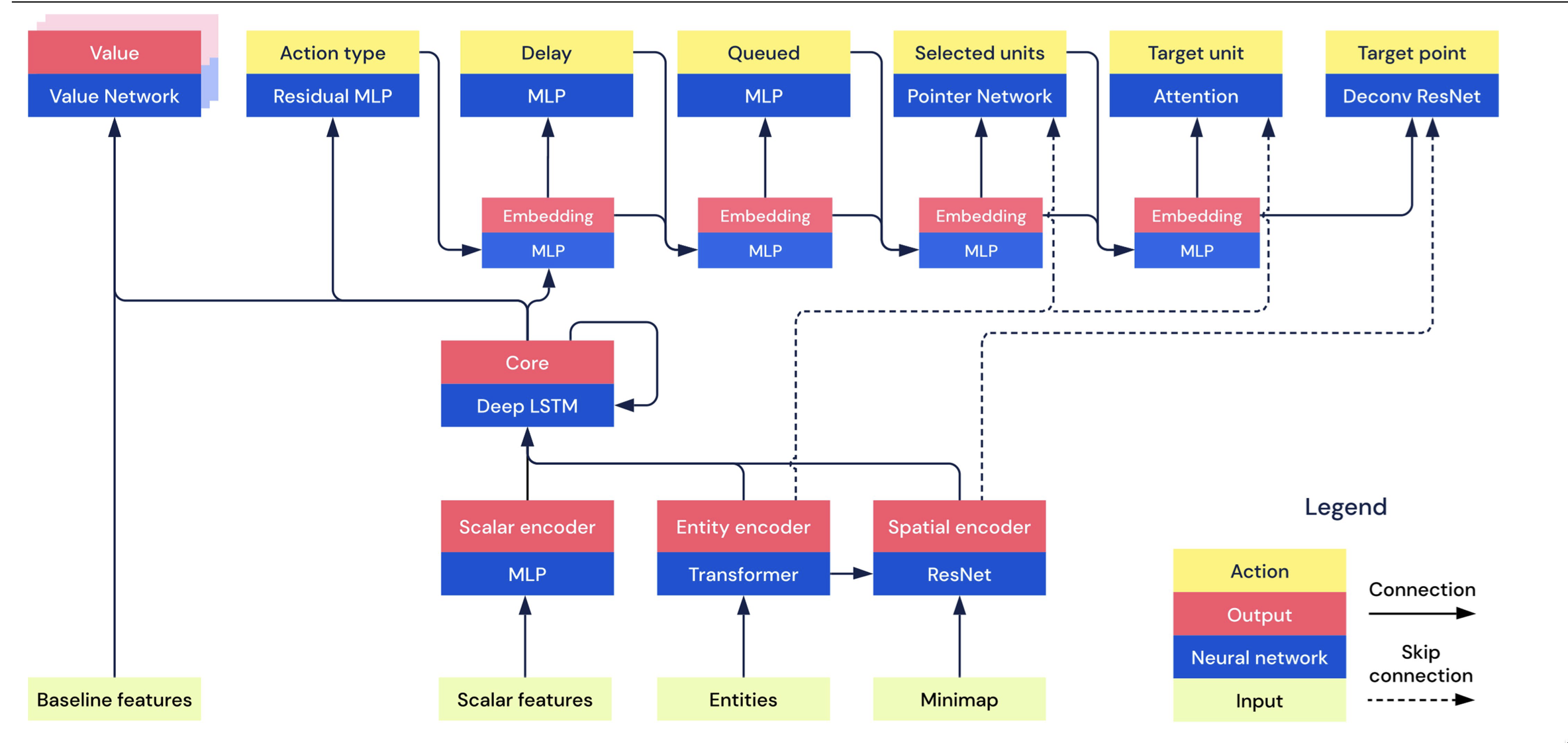
对于强化学习算法,整体模型采用了Actor-Critic的架构.
2.1 策略网络训练
整个强化学习模块采用的为off-policy的方式进行数据的采集和训练,因此添加了ex-buffe和重要性采样
在重要性采样的过程中基于V-trace限制了ratio比值为(0,1)
对于advatage的计算使用了UPGO方法:
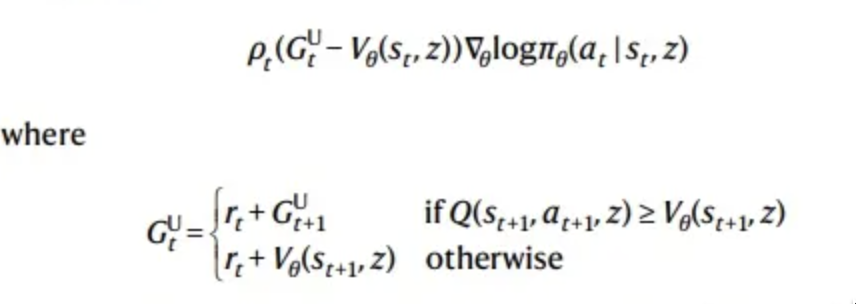
2.2 价值网络训练
- 依然采用mse计算Q和V的拟合度
- 对于Q的计算采用TD(λ)算法
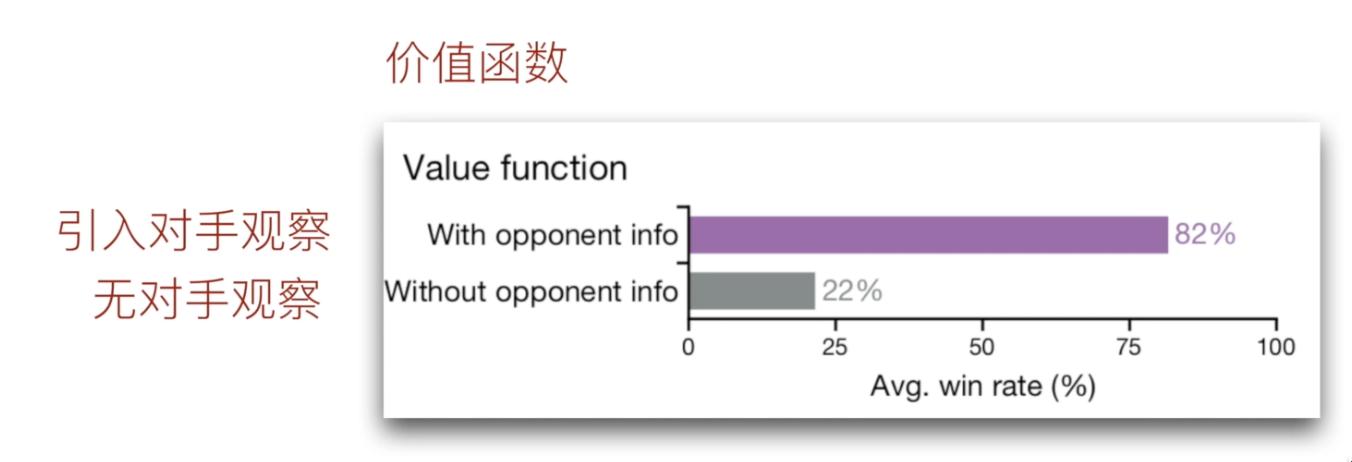
- 将自身observations和对手的observations一起纳入输入量,综合自身和对手的信息得到评价值
3. 模仿学习
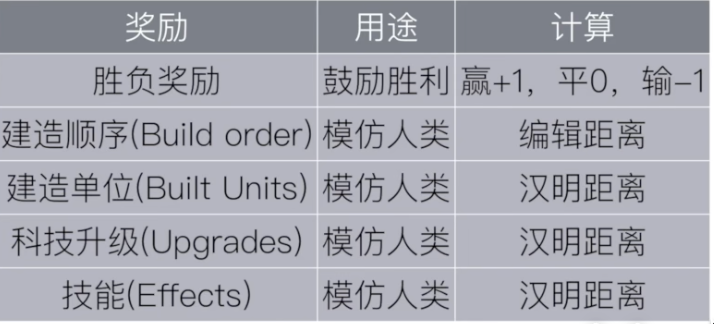
- 由于在强化学习过程中,只有胜利或者失败才能获得一个较高的reward,在训练过程中存在稀疏奖励的问题,采用模仿学习的方法,基于人类经验给予伪奖励。
- 若agent的动作或者当前的observations人类经验中出现过,则基于一个正奖励。
4. 联盟训练
4.1 self-play
方法:自己和自己进行博弈
缺陷:容易行程策略循环
改进方法:FSP(ficitious self-play),训练过程中存下若干快照,从而形成种群,均匀的在种群中挑选对手进行对战。
FSP缺陷:在种群中存在若干太菜的对手,对战胜率为100%,浪费时间没有训练意义
4.2 PFSP(prioritized ficitious self-play)
方法:按照胜率从种群中挑选对手,给高手一个高概率被挑选的机会,即agent更倾向于与高手对抗
A(target agent)挑选B的几率:

对于P(A beats B)采用ELO算法采用隐藏分机制【需要大量比赛得到一个客观的值】
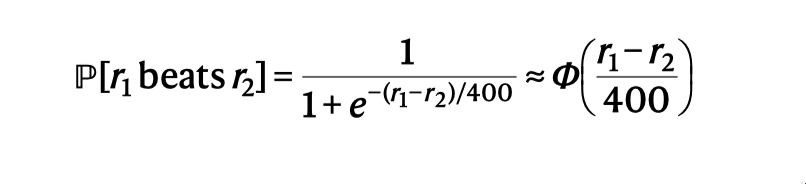
4.3 league training
AlphaStar将所有的agent分为三类:
- main agent: 重点训练的agent即target agent
- league exploiter: 与整个league对战,用于发现全局弱点
- main exploiter: 与当前main agent或者历史main agent对战,用于发现main agent的弱点
对战方式:
main agent训练:
(1) 个数设置
每个种族各一个(SW2游戏中共三个种族,一个种族设置一个)
(2)对手挑选
- 50%从league里选(选择方法为PFSP,F函数为(\(f(x) = (1-x)^{p},p=2\)))
- 35%与自己对战
- 15%与能打败我的league exploiter对战或者历史版本的main
agent(选择方法为PFSP,F函数为(\(f(x) =
(1-x)^{p},p=2\)))
- 若一个历史版本的main agent以70%概率战胜当前main agent说明当前main agent退化了
- 若main agent以30%打败league exploiter,说明league exploiter发现了main agent弱点
(2)存档方式:
每隔2*1e9个时间步存档一次
league exploiter训练:
(1) 个数设置
每个种族各2个(共6个)
(2)对手挑选
按照PFSP与整个league对战((选择方法为PFSP,F函数为(\(f(x) = (1-x)^{p},p=2\))))
(2)存档方式:
- 若该league exploiter以70%打败所有agent,或者距离上次存档间隔2*1e9时间步
- 每次存档后有25%的概率将参数重设为监督学习预训练的参数
main exploiter
(1) 个数设置
每个种族各1个(共3个)
(2)对手挑选
step1: 从三个当前main agent随机选择一个,执行step2
step2: 若以高于10%的概率战胜他则,进行对战,否则执行step3
step3: 从所有历史版本的main agent按照PFSP(选择方法为PFSP,F函数为(\(f(x) = (1-x)x\)))中挑选对手进行对战
(2)存档方式:
- 若该main exploiter以70%打败所有main agent,或者距离上次存档间隔4*1e9时间步
- 每次存档后就重设为预训练参数
5. 消融实验探讨
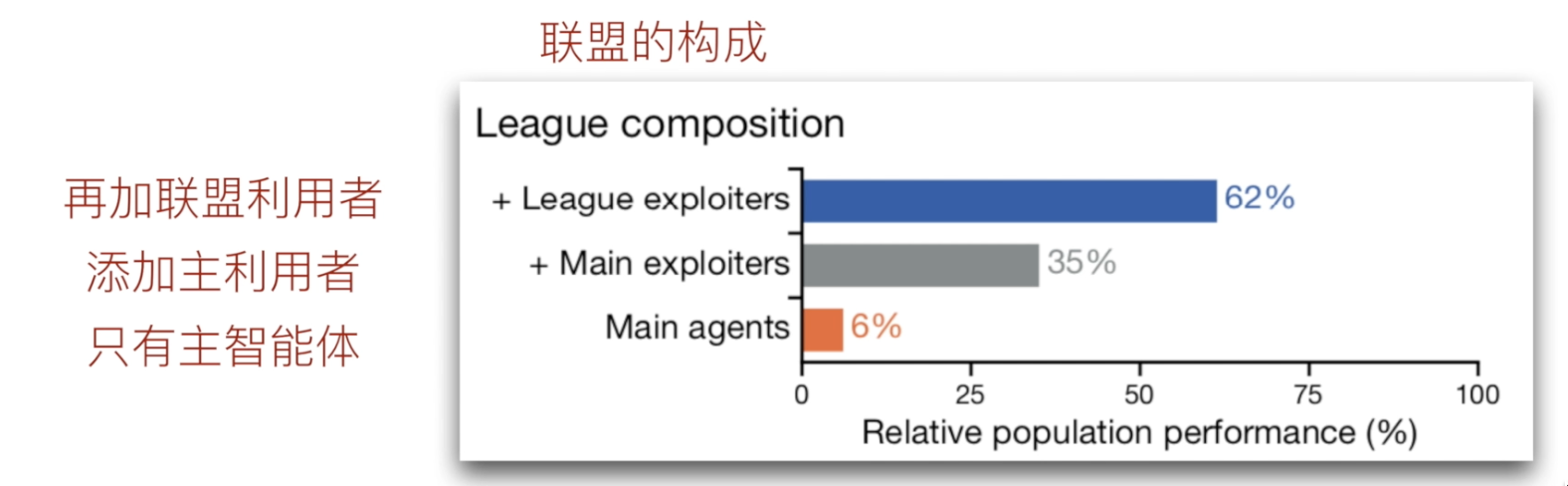
5.1 league构成消融
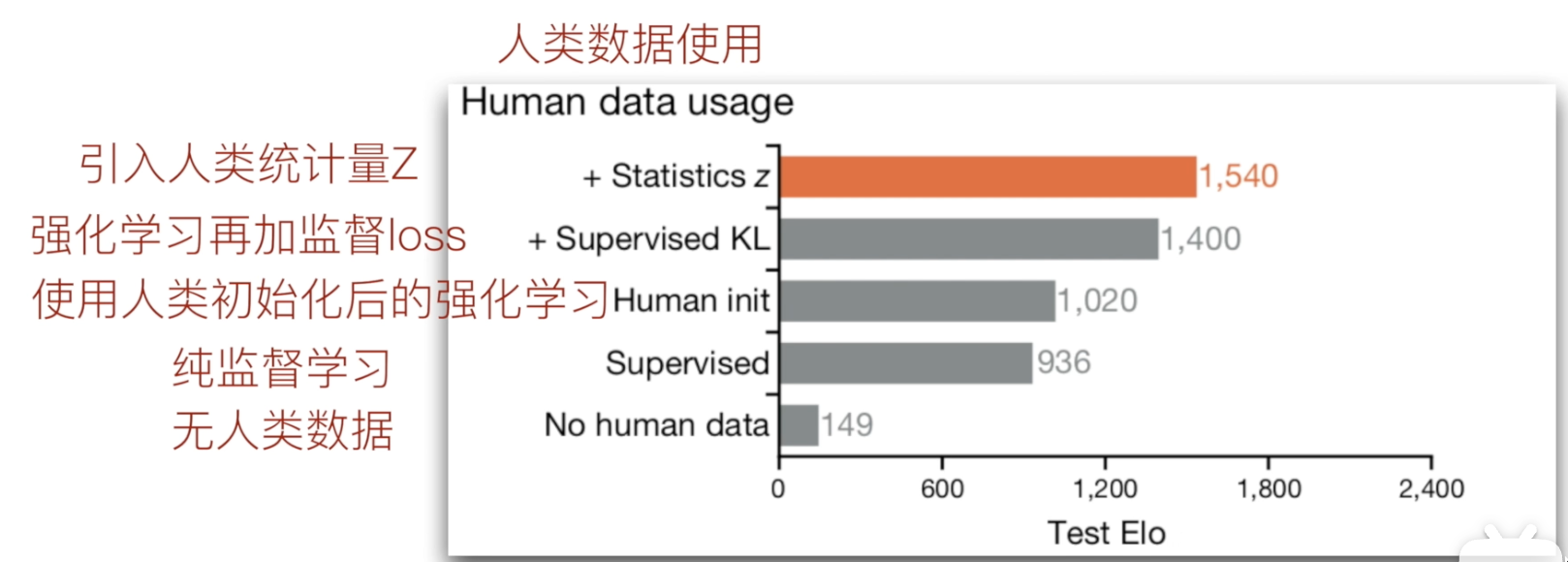
5.2 人类经验使用方式消融实验
5.3 对手observations消融