
知识蒸馏
本文整理自B站UP主“同济子豪兄”
原视频链接:https://www.bilibili.com/video/BV1gS4y1k7vj/?spm_id_from=333.337.search-card.all.click&vd_source=54a0edf8490a6a72a5e82c4e543fc3e2
知识蒸馏的意义:将大规模网络训练参数进行压缩,更加便于终端或者移动端的部署
其他模型压缩方法:
- 权值量化
- 剪枝(权值剪枝/通道剪枝)
- 注意力迁移
信息熵的处理
hard target:例如在图像分类问题中,对于类别的判断为纯0/1判断,对于这种处理银含了一个图片完全是XX或完全不是XX,此处理方法对于含有的信息量太少,或是信息熵太少,对于真正的现实问题处理可能会有较高的准确率,但是并不是处理相似度所有问题的一个好方法。

soft target:也例如在图像分类问题中,给于每个类别一定的置信度,而不是完全的0/1,提高分类结果的信息熵含量。

通过以上所述,对于soft target衍生的soft label含有更多的“知识”,或直说含有更多的信息。
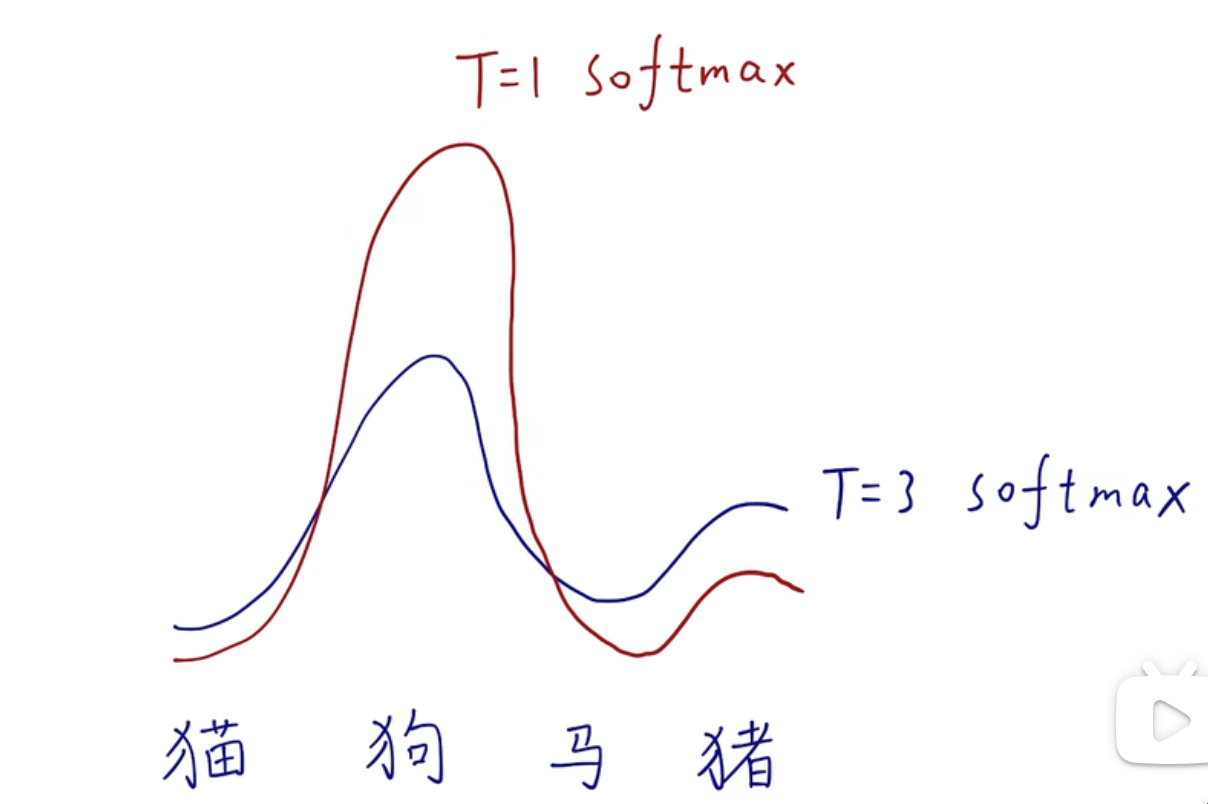
蒸馏温度
\[ q_{i} = \frac{exp(z_{i}/T)}{\sum_jexp(z_{j}/T)} \]
T为蒸馏温度,当T为1时,整个式子即为softmax函数
蒸馏过程
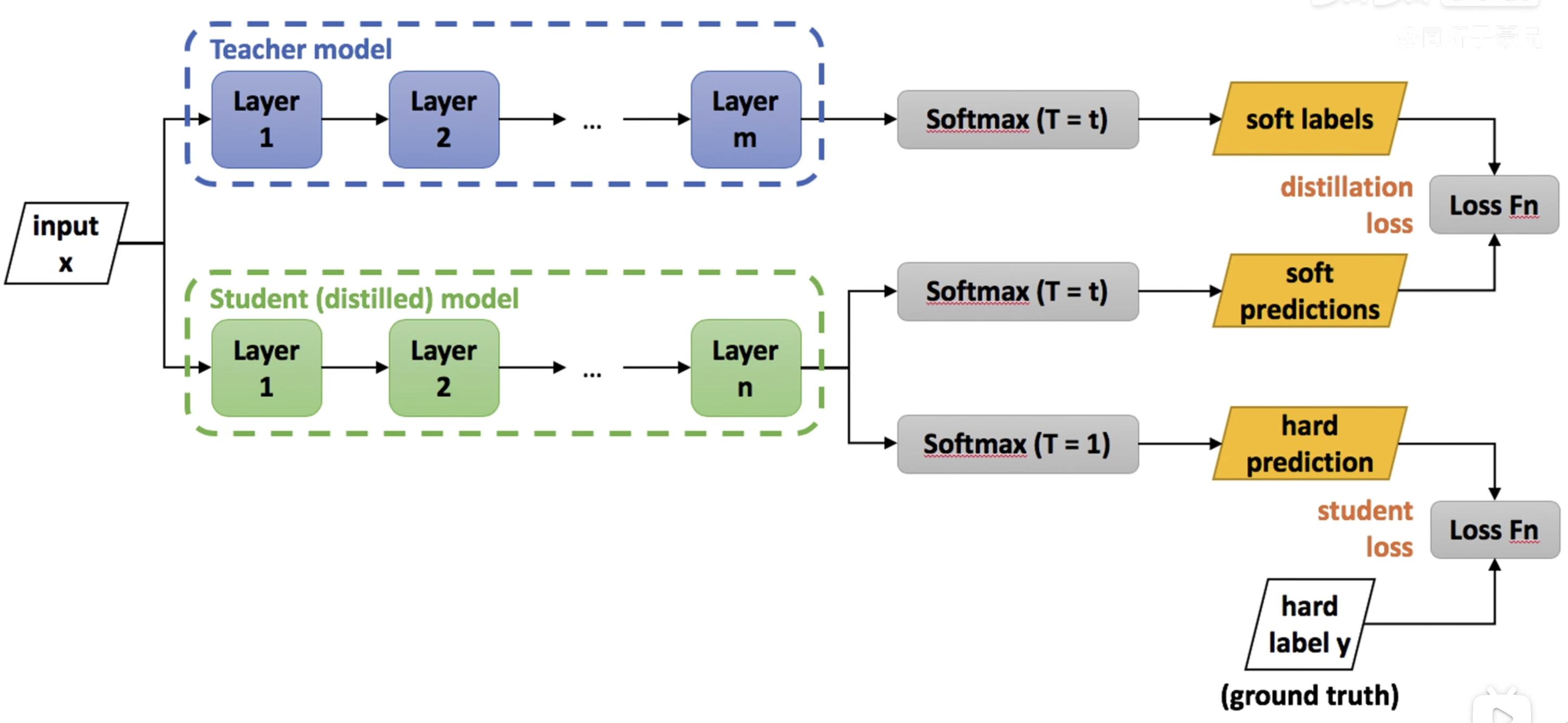
Teacher Model:已经训练好的model
Student Model:准备压缩的model
Step:
- loss 1(soft loss):
- 教师网络经过蒸馏温度为T的softmax获得分类标签作为loss1的目标值
- 学生网络经过蒸馏温度为T的softmax获得分类标签作为loss1的预测值
- 计算误差获得loss1
- loss 2(hard loss):
- 学生网络经过蒸馏温度为1,即原生的softmax,获得loss2预测值
- 通过ground truth和softmax的预测值计算loss2
- loss1和loss2加权求和作为总的loss值
知识蒸馏优势
- 模型压缩
- 优化训练,防止过拟合
- 无限大、无监督数据集(海量图片经过teacher model获得softlabel可以作为student model的soft loss)
- 少样本学习
迁移学习和模型蒸馏的区别
迁移学习(同一个model架构,不同的sample):同一个模型,之前训练网络使用的识别猫狗的数据集,现在为识别植物的数据集,模型就从识别猫狗的模型变为识别植物的模型
模型蒸馏(不同的model架构,同样的效果):不同的模型,同样的知识
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Yue C.H. Site!